In today's tech-driven world, Machine Learning stands as a groundbreaking force, transforming how we analyze data, make predictions, and automate complex tasks. In this blog, we'll explore Machine Learning, with a special emphasis on the popular tool, Scikit-Learn. Before delving into Scikit-Learn's details and applications, let's first grasp the basics of Machine Learning.
Machine learning is a branch of artificial intelligence (AI) that allows systems to automatically learn from their experiences and advance without explicit programming. If the performance of doing a particular task is improving with experience, then we can say the machine or model is learning.
Machine Learning tasks can be broadly categorized into three main types:
1. Supervised Learning: In Supervised learning, an algorithm is trained on a labeled dataset. The labeled data set contains both input and output parameters. Two types of Supervised Learning: Classification and Regression.
Classification: It is used to identify which category an object belongs to. For example, emails are categorized by Gmail into groups such as social, promotions, updates, primary, and forums.
Regression: A task is referred to as regression if the expected result includes one or more continuous variables. Take the city's temperature, for instance. Here, the temperature is constantly rising or falling.
2. Unsupervised Learning: This type of learning works with unlabeled data and looks for hidden structures or patterns in the collection. Clustering and dimensionality reduction are common unsupervised learning tasks.
3. Reinforcement Learning: The process of teaching an agent to make decisions in a given environment in a way that maximizes a reward is known as reinforcement learning. This type of learning is prevalent in applications like game-playing and robotics.
In this blog, we'll focus on Scikit-Learn, a robust and user-friendly library for Machine Learning in Python.
Scikit-learn is one of the most popular libraries in Python that helps in implementing Machine Learning algorithms. It simplifies extremely complex machine-learning problems. It’s built upon libraries like NumPy, pandas, and Matplotlib.
The functionality that scikit-learn provides includes:
* Regression, including Linear and Logistic Regression
* Classification, including K-Nearest Neighbors
* Clustering, including K-Means and K-Means++
* Model selection
* Preprocessing, including Min-Max Normalization
We will discuss some of the machine learning algorithms with scikit-learn. Before that, install scikit-learn by running the following command.
pip install -U scikit-learn
To implement a Machine Learning model, the steps we are going to follow include:
1. Loading dataset
2. Separate dataset into train and test data
3. Fit the model/algorithm and make predictions on our data
4. Evaluating model
1. Loading dataset:
The first thing we should do is load data. Scikit Learn comes with a few small datasets called toy datasets. To access those datasets, we need to import the datasets module from the sklearn library.
from sklearn import datasets
dir(datasets)
iris = datasets.load_iris()
digits = datasets.load_digits()
diabetes = datasets.load_diabetes()
wine = datasets.load_wine()
boston = datasets.load_breast_cancer()
print(iris.data) # Prints the features of the Iris dataset
print(iris.target) # Prints the target labels (species)
print(iris.feature_names) # Prints the names of the features
print(iris.target_names) # Prints the names of the target classes.
print(iris.DESCR) # Prints a description of the dataset.
The dir() function is used to list the attributes and methods available in the datasets module.
load_*() functions provided by the datasets module load several datasets. Each function loads a specific dataset into a variable (iris, digits, diabetes, wine, Boston) by assigning the dataset object returned by the function to these variables.
load_iris() loads the Iris dataset. The Iris dataset is famous in machine learning, commonly used for classification tasks. It contains features related to iris flowers and their species, making it a good example for machine learning exercises.
load_digits() loads another dataset, the Digits dataset.
load_diabetes() loads the Diabetes dataset, which contains data related to diabetes patients.
load_wine() loads the Wine dataset, which contains information about different types of wine.
load_breast_cancer() loads the Breast Cancer dataset, which contains data on breast cancer patients.
You can access the toy datasets in this way.
Now, to generate your datasets, depending on the data and its format, you can use different libraries. If the data format is:
* CSV, SQL, JSON, Excel - Use Pandas library
* Image, video, array - Use NumPy library
* Binary - Use Scipy library
Here, I am using a CSV dataset from Kaggle. You can download it here. So let's use the Pandas library to load it. If you are new to Pandas, you can refer to our blog How to Read and Write Excel or CSV Files Using Pandas
import pandas as pd
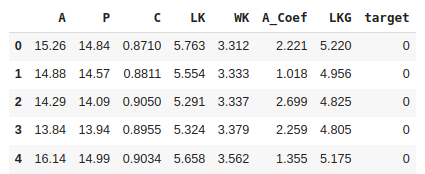
seed_data = pd.read_csv('Seed_Data.csv')
print(seed_data.head())
Output:
2. Separate dataset into train and test data:
After loading the data, the next step is to separate the dataset. We use some of our data for testing rather than all of it for training. So we will split the dataset into training and testing sets. It is necessary because, during training, we acquire knowledge, and testing determines how successfully we may use that information.
In Scikit-learn, the train_test_split function from the sklearn.model_selection module is used to split data into training and testing sets. This function allows you to specify the proportion of the data to allocate for training and testing purposes.
from sklearn.model_selection import train_test_split
X = seed_data.drop('target', axis=1)
y = seed_data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
Here, first, we partition our dataset to X and Y where X contains all input feature data and Y contains target labels. Then we split this dataset into train and test sets. test_size=0.2 indicates that 20% of the data will be allocated for testing and the remaining 80% for training. You can adjust this percentage as needed. If no percentage is given, 25% will serve as the test set and 75% will serve as the training set. random_state sets the seed for random number generation. It ensures that the data splitting is deterministic and reproducible. Setting random_state allows you to obtain the same split when the code is run multiple times.
After splitting the data using train_test_split, you will have four sets of data:
X_train: Training set of input features.
X_test: Testing set of input features.
y_train: Training set of target labels.
y_test: Testing set of target labels.
You can then use X_train and y_train to train your machine learning model and X_test to evaluate its performance. This separation of data helps in assessing how well the trained model generalizes to new, unseen data (which is represented by the testing set).
3. Fit the model/algorithm and make predictions on our data:
After splitting the data into training and testing sets, you can choose an appropriate machine learning algorithm (such as Linear Regression, Random Forest, Support Vector Machines, etc.) and train it using the training data. Training a model is a fundamental aspect of the entire Machine Learning workflow.
In Scikit-Learn, any model can be trained easily with the fit() method. For that, we can use any model, instantiate it, and call the fit() method along with our training data (X_train and y_train). This step involves the model learning the patterns and relationships within the training data.
In this blog, I am using the model SVC (Support Vector Classifier). The Support Vector Classifier (SVC) is a supervised machine learning algorithm used for classification tasks. It belongs to the family of Support Vector Machines (SVMs), which are powerful and versatile algorithms for both classification and regression.
First, import the svm module from Scikit-learn, which provides support for Support Vector Machines.
from sklearn import svm
clf = svm.SVC()
clf.fit(X_train, y_train)
svm.SVC() creates an instance of the Support Vector Classification (SVC) algorithm. SVC stands for Support Vector Classifier. It's a type of SVM used for classification tasks. The clf variable here is an instance of the SVC model, which will be used for training and making predictions. clf.fit(X_train, y_train) trains (fits) the SVC model using the training data (X_train and y_train).
After the fit() method is executed, the clf variable contains a trained SVM model that has learned patterns and relationships from the provided training data, and it's ready to make predictions on new, unseen data using the learned patterns.
Now that our algorithm has been trained on the training data, we can make predictions on the test dataset (X_test).
pred_clf = clf.predict(X_test)
Output:

After executing this line, the variable pred_clf contains the predicted target labels generated by the SVM classifier for the corresponding input features in the testing set. These predicted labels are based on the patterns and relationships learned by the model during the training phase.
The predict() method in Scikit-learn is used to generate predictions based on the input data provided to the trained model. In this case, it applies the learned model to the testing data to make predictions on unseen samples. These predicted labels (pred_clf) can then be used for further evaluation or analysis, comparing them with the actual target labels (y_test) to assess the model's performance.
4. Evaluating model
In Scikit-learn, evaluating a machine learning model involves assessing its performance on unseen data using various metrics suitable for the specific task, such as classification, regression, clustering, etc.
Here we will discuss common evaluation metrics for classification problems:
Accuracy: The proportion of correctly classified instances, ie, how often is the classifier correct.
Precision: The ratio of true positive predictions to the total predicted positives.
Recall (Sensitivity): The ratio of true positive predictions to the total actual positives.
F1-score: The harmonic mean of precision and recall, providing a balanced measure between precision and recall.
Confusion Matrix: A table showing the counts of true positive, true negative, false positive, and false negative predictions.
Classification Report: It provides a summary of important metrics such as precision, recall, F1-score, and support for each class in the classification problem.
Compute evaluation metrics based on predictions and actual target values.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
accuracy = accuracy_score(y_test, pred_clf)
cm = confusion_matrix(y_test, pred_clf)
clf_report = classification_report(y_test, pred_clf)
print('Accuracy Score: ',accuracy)
print('Classification Report: ', clf_report)
print('Confusion Matrix: ',cm)
Output:
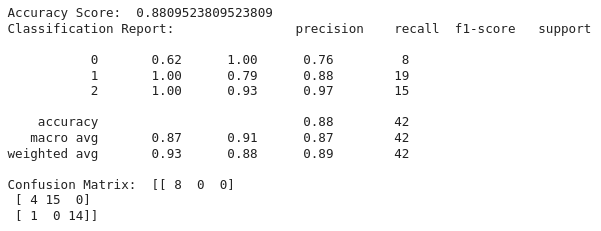
In this way, we can use Scikit Learn to implement various Machine Learning algorithms. In wrapping up the discussion about Scikit-Learn and its role in Python-based machine learning, I've mainly focused on explaining one algorithm called the Support Vector Classifier (SVC). However, there's a whole world of other powerful algorithms within Scikit-Learn waiting to be explored!
In future blogs, I'll be diving into different algorithms like the Random Forest Classifier (RFC), K-Means, and many more. Each of these algorithms has its unique way of solving problems using machine learning.